As I use linux as normal operating system, and prefer gvim very much. I would like to share some skills to help keep your hands away from mouse bracing the high efficient way of working. Especially for the survive stage vim newbees. I hope the article will help you get into the translation work faster than spending long time learning vim from 0.
1.MOVE
移动
1.1 move between msgstr
msgstr间移动
The basic item of .po file is msgstr, when whose state is untranslated and fuzzy need working on. So jump between the msgstr is very simple:
在翻译中基本单位是msgstr,需要翻译的状态是:未翻译和fuzzy,在这两种状态直接的跳跃方法很简单:
In both normal and insert state, SHIFT+F1, next untranslated, SHIFT+F2, pre untranslated
SHIFT+F5, next fuzzy, SHIFT+F6, pre fuzzy.
两种状态下,SHIFT+F1,下一条未翻译,SHIFT+F2,上一条未翻译。
SHIFT+F5,下一条fuzzy,SHIFT+F6,上一条fuzzy。
If you would like to find a pre msgstr which you just finished to modify, command "`." is a good choice, right back to the specific location you edited.
这里有个小的技巧是如果想要找到上一条翻译的,打算修改,可以使用“`.”命令,直接跳回上次编辑的位置。
1.2 move inside msgstr
msgstr 内移动
Facing a long sentence or changing a fuzzy translation may need us jump inside a msgstr. It is obvious to be stupid if we just use "jkhl" to jump one step a time. So we could jump a word forth or back by using "WwBb". In other situation, when words mixed with tag or other items using f(find in next) or F(find in pre) will be better. We take an example:
当一个比较长的句子,或者是要对 fuzzy 状态的句子进行修改时,句子中间的跳跃如何更方便,可以预见,用jkhl来一个一个单词的跳跃太麻烦了,所以,以单词为单位的 WwBb 就非常方便。在其他情况下,当单词掺杂符号,例如含有标签的更好的方式是f(向后查找)F(向前查找)某个特殊的字母或者符号。例如:

---copy the original text --- (insert mode) SHIFT-F3
---delete from tag to end --- fi(to the word 'is') ct"

--- after translate first line to next line
--- delete the context in second line --- ci"

--- delete text before tag --f<h dT"

Just to show the skill, it is not the best.
BTW, gvim under windows has better experience for the input methods. For example, I use fcitx by which Chinese will be identified only as a whole word for when the f (find) the input method still stay English environment. The ibus or fcitx input methods need more support, with better input method, we will be more efficient. If you have to work under linux, I recommend GNOME whose integrated Input Method is good.
此外一个个人的小小想法,在windows下使用gvim的效果不错,虽然被很多朋友们诟病,但是windows下由于有更好的中文输入法支持,在f命令后可以接中文,这样在查找起来非常方便,而linux下的ibus,fcitx在这方面的支持较弱,整个中文句子中要修改某个词的时候,跳到该处比较麻烦。并且fcitx在每次跳到下一条的时候输入法都会变回英文,不能保持上一次状态。
1.3 move about tag
tag 的移动
Context inside a tag could be identified, so use "cit" will clear context and cursor will stand inside the tag. For example:
cit,进入tag的内容修改。下面例子:

---cursor in the scope of tag
---magic --- cit

2.delete
删除
Delete is very very simple, just select a region and d.
删除旧的内容,增添新的内容是很常见的事情,在gvim下,最傻瓜的办法是v(可视)
用jkhl标定范围,d删除。对于不愿意记很多命令的新手,这是最普遍的解决办法。
Be careful of a(all), i(in), t(tag) when use the command d(delete).
2.1 a 删除
想要删除整个""?想要删除整个标签?试试da",dat。想要在删除后直接进入编辑模式?ca",cat。
2.2 in 删除
想要删除""中的内容,或者标签中的内容,将2.1中的a改成i试试,非常好用。
2,3 t 删除
只想要删除一部分,从当前到某个字母,数字,标签或者"?跳到删除开始的地方,dt(目标),注意,t",删除到",不包含"。
3. copy
复制
Why copy is different , because where the text we copy saved, there are something to know. How we use register is very important.
Registers are the default space for vim command y and d.
复制分为选定和复制两个阶段,对区域的选择可以用v来划定,成行的选择可以用数字yy来选择区域。那么重点讲寄存器技巧。
寄存器是Vim用来存储文件的临时空间,当使用命令y(yank)或者d(delete)复制删除文本是,该文本就会被保存在寄存器里,通过p(put)命令插入刚删除或复制的内容。
3.1 number register
数字寄存器
The read-only registers 0 through 9 are your “historical record” registers. The register 0 will always contain the most recently yanked text, but never deleted text; this is handy for performing a yank operation, at least one delete operation, and then pasting the text originally yanked with "0p.
The registers 1 through 9 are for deleted text, with "1 referencing the most recently deleted text, "2 the text deleted before that, and so on up to "9.
在normal模式下输入:reg,就会看到很多"开头的数字,这些都是数组寄存器,存放最近删除和复制的文本。
数字寄存器有十个,分别是:"0,"1,"2..."9,寄存器"0保存上一次复制操作的文本,"1到"9保存最近9次删除的文本行。p命令粘贴的是哪个寄存器的内容呢,有时候是"0,有时候是"1。总的原则是粘贴最近一次删除或者复制的内容。
3.2 Capital register
字母寄存器
"a,"b,"c...are the names of capital registers, you must know there are 26 capital registers.
How to copy context to capital register? Their name plus p like "ay(copy selected to "a).
If we need added more to the register, use the name in Capital like "Cdd(add the deleted line to the end of "c register str.)
"a,"b,"c...都是字母寄存器,执行:reg时可能看不到,稍后会有,如何将指定内容复制到字母寄存器里:寄存器名称+p。
例如我们要把当前行的内容放到"a寄存器中,咋normal模式下输入"ayy,粘贴则是在normal模式下,"ap即可。如果讲寄存器名称大写,则表示追加,如"Cdd,作用是把当前行删除追加到"c寄存器中。
3.3 Other register
其他寄存器
"": unnamed register, store the latest delete or yank
"":无名寄存器,保存最近一次删除或复制内容。
"-: the small delete register, store the delete small str with command dw or x
"-:小删除寄存器,删除的单词或者字母保存在此。
"+: system clipboard, things here could be pasted to everywhere in system.
"+:系统剪切板,保存在里面的内容可以直接在系统的其他应用中ctrl+v粘贴的。
Here is a simple example of how to use register between more than one file :
在翻译中,如果存在对照文本,在查找单词时,建议专门将单词放在字母寄存器中,可以在参考文本中查询多次。举例:
If I need to find the sentence contains "enhancements" in the left file to give a hint.
在右侧文件中包含 enhancements 的句子需要在左侧文件中寻找提示。
---select the word ---vw
---yank to register --- "ay

---jump to the left window --- ctrl+x --- h
---find mode --- /
---from register --- ctrl+r
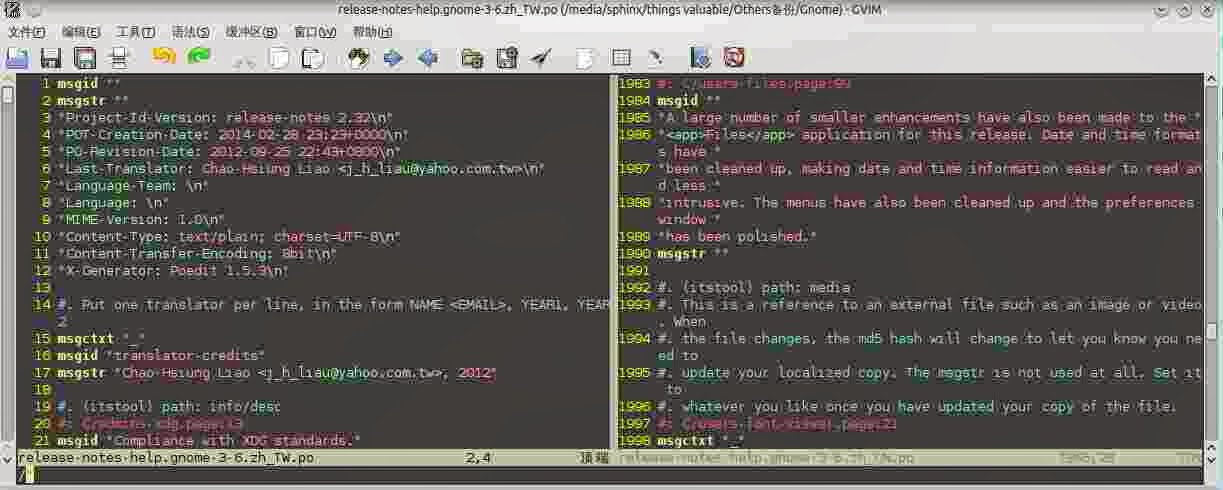
----from register a --- a

If you need the help of google or csslayer, use "+ register will really help you without mouse.
如果需要将单词或内容放到google translator或者csslayer网站查询,建议使用"+。
I hope more people could handle the basic tool for translation as soon as possible, enjoy translation itself and share the skills with others.
希望大家可以快速的适应gvim这个良好的翻译工具,体会vim的方便快捷,并分享这其中的小技巧~~
This is a good post. Useful not only for translators, but also programmers and XML editors.
回覆刪除